How to Spot and Fix Hidden Data Dependencies in Your Credit Models
Learn how lenders can prevent model risk, avoid vendor lock-in, and strengthen credit data supply chains using resilient alternative data strategies.


Modern credit risk models increasingly depend on alternative data. According to Nova Credit, 43% of lenders now supplement traditional credit scores with digital and behavioral signals.
From email and phone intelligence to subscriptions and online activity, third-party data helps lenders see beyond credit histories.
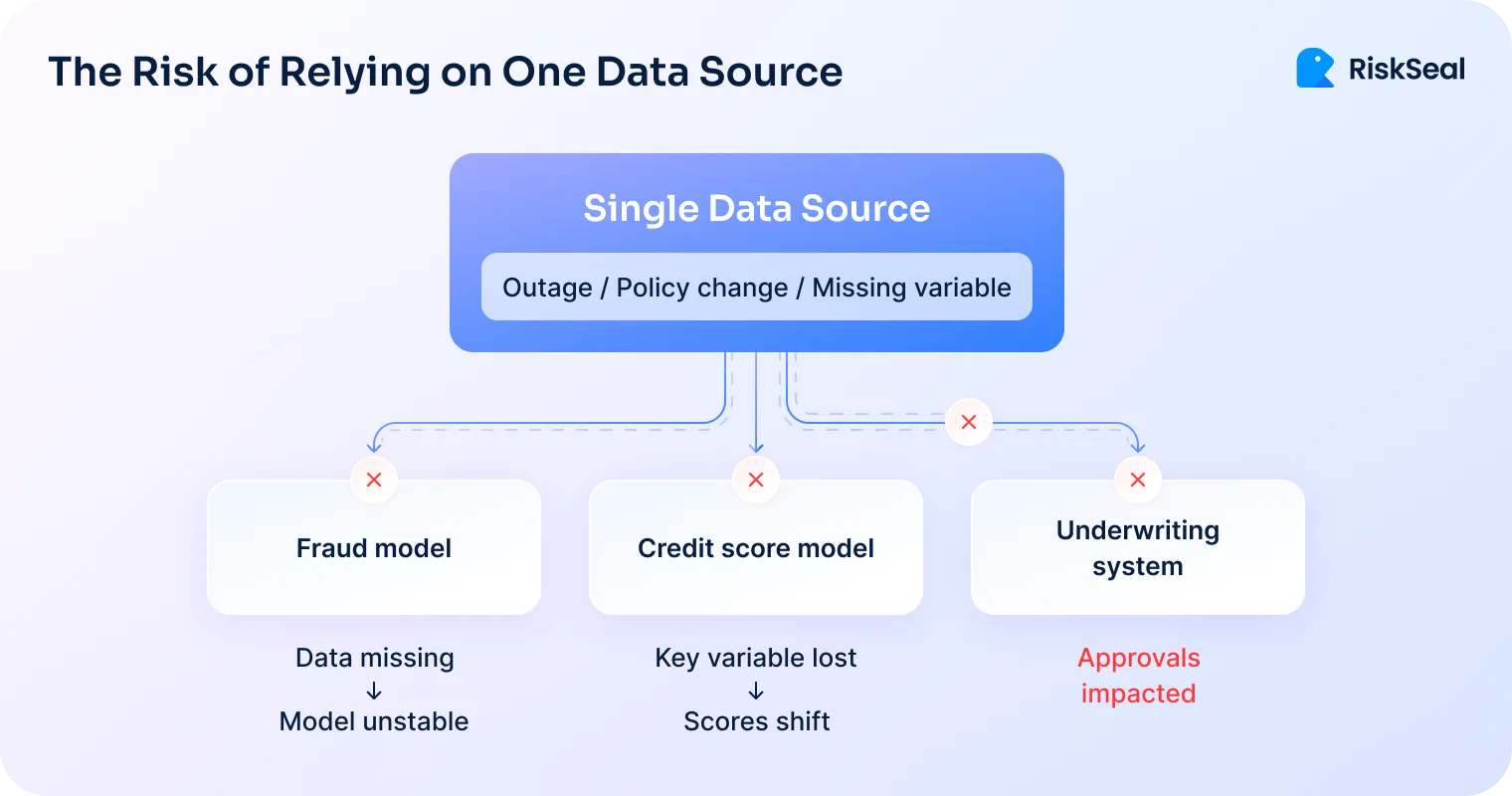
But there’s a growing structural risk: over-reliance on a single alternative data provider or signal type.
If that data source changes or disappears, lenders face sudden drops in accuracy, compliance exposure, and even downtime. The system becomes fragile.
At RiskSeal, we’ve watched this pattern emerge across the industry for years. That’s why we’re raising it now. Because data dependency isn’t a technical issue. It’s a structural risk.
How “great data” can weaken model risk management
Not all fragility comes from bad data. Sometimes, the problem starts with good data used too heavily.
Modern alternative credit data vendors deliver powerful signals, including:
- Phone reputation scores based on long-term SIM stability
- Email age and trust metrics that predict fraud likelihood
- Device and IP consistency that verifies identity and location
Each of these can improve model performance.
But when one signal type or feature dominates the input mix, the model becomes imbalanced.
For example, an e-commerce behavioral feed might perfectly predict spending intent today.
But if that provider changes data access or coverage tomorrow, every model depending on it risks immediate degradation.
This is a classic case of signal overfitting. Model accuracy looks exceptional in validation but collapses in production once the underlying data shifts.
It’s also a transparency issue.
Many lenders don’t realize how much of their model’s variance comes from a single vendor’s features until a disruption occurs.
Explainability tools can help, but if the data itself is opaque or proprietary, even the best risk assessment teams struggle to see the exposure.
The result? A false sense of confidence, until it’s too late.
The business and operational impact of data vendor dependence
1. Single-point failure scenarios lenders should prepare for
Depending too heavily on one data vendor turns that vendor into a single point of failure.
When their systems, prices, or policies change, your risk models feel the impact immediately.
Vendor outage
A vendor outage can mean instant downtime for scoring or verification workflows.
This isn’t hypothetical.
Between 2019 and 2021, LinkedIn tightened access to its public data after the hiQ Labs v. LinkedIn case.
Dozens of analytics platforms that relied on employment-related data lost access overnight. Even compliant vendors saw their APIs throttled or deprecated.
The result was stalled products, lost clients, and broken data pipelines. All triggered by a single upstream change.
Pricing shock
Pricing shocks can create the same effect.
In early 2023, Twitter (now X) ended free API access and replaced it with a high-cost enterprise tier.
Companies that depended on Twitter data for social graph insights suddenly faced costs in the tens of thousands per month.
For smaller or mid-size data providers, this meant an immediate and unsustainable increase in acquisition cost per applicant.
Policy change
Policy shifts can be just as disruptive.
When Google released Android 11 in 2020, it restricted broad access to device storage and identifiers.
Many SDKs that relied on that data for behavioral or fraud detection lost a key input channel.
The change wasn’t malicious; it was regulatory. But it still broke downstream models that weren’t designed with redundancy.
Across these examples, the pattern is clear.
When one source dominates your data pipeline, any disruption in that source cascades across your entire system.
What starts as a small policy change can quickly become a full-scale scoring outage.
2. Regulatory and audit headaches exposing risk model governance gaps
Overreliance on proprietary data introduces another form of risk – opacity.
Financial regulators now expect explainable models where each input’s contribution to the score can be measured and justified.
But if critical variables come from a “black box” vendor that won’t disclose how features are built or updated, lenders face a compliance dilemma.
Auditors ask:
- Which feature influenced this decision?
- Can you trace that feature to an interpretable signal?
- Is it fair across demographics?
Without transparency from the vendor, those questions become difficult to answer. Especially under frameworks like the EU AI Act that regulate digital footprint AI analysis.
3. Model drift and validation challenges in lending data environments
When one provider’s data changes, models drift fast. This could be due to new collection methods, updated scoring logic, and reduced coverage.
Risk assessment teams may notice accuracy drops. But they can’t easily isolate the root cause.
With multiple dependent features from the same source, the drift becomes correlated across variables, compounding error rates.
What's worse, overfitting doesn't always solve the problem. Especially if the problem lies in the data quality rather than the modeling.
Vendor dependence isn’t just a data science issue. It’s a governance and business continuity problem.
Vendor lock-in: the long-term cost of convenience in credit risk automation
Vendor lock-in rarely begins as a deliberate choice. It starts with convenience.
A single provider is easier to integrate, support, and bill. Their data fits smoothly into your systems.
Your data engineers know the scheme. Your risk managers have already tuned their models around it. In a fast-moving lending environment, that efficiency feels like progress.
But over time, this convenience hardens into dependency.
Workflows, validation tools, and even hiring decisions start to orbit one vendor’s technology stack.
Switching becomes more than a technical project. It turns into a cultural and operational upheaval.
Teams resist change because retraining, re-testing, and re-certifying models all take time and money.
As dependency deepens, several long-term issues begin to surface:
- Reduced agility. Model updates and new data integrations must align with one vendor’s infrastructure, slowing iteration cycles.
- Rising budgets. Renewal prices, data usage fees, or API access tiers tend to increase as your reliance grows.
- Vendor leverage. Providers gain negotiation power, often introducing stricter contract terms or usage restrictions.
- Innovation friction. Teams hesitate to experiment with new signals or modeling frameworks that fall outside the incumbent vendor’s structure.
The cost isn’t only financial. Lock-in quietly erodes negotiation power and limits optionality.
Vendors recognize when they’ve become indispensable. What was once a flexible partnership becomes an asymmetric relationship.
Lock-in also slows innovation. When every new initiative must conform to a single vendor’s data structure, experimentation suffers.
Lenders hesitate to test new sources or alternative modeling approaches because they no longer fit the established pipeline.
The outcome is subtle but damaging: operational comfort turns into strategic vulnerability. Dependency doesn’t just limit flexibility. It reshapes how teams think about what’s possible.
What begins as efficiency ends as captivity.
.svg)
.webp)
Diversifying data sources for a stronger scoring model resilience
Resilience doesn’t mean collecting every possible dataset. It means building balanced diversity across your data layers.
Diversify your data foundation for balance and depth
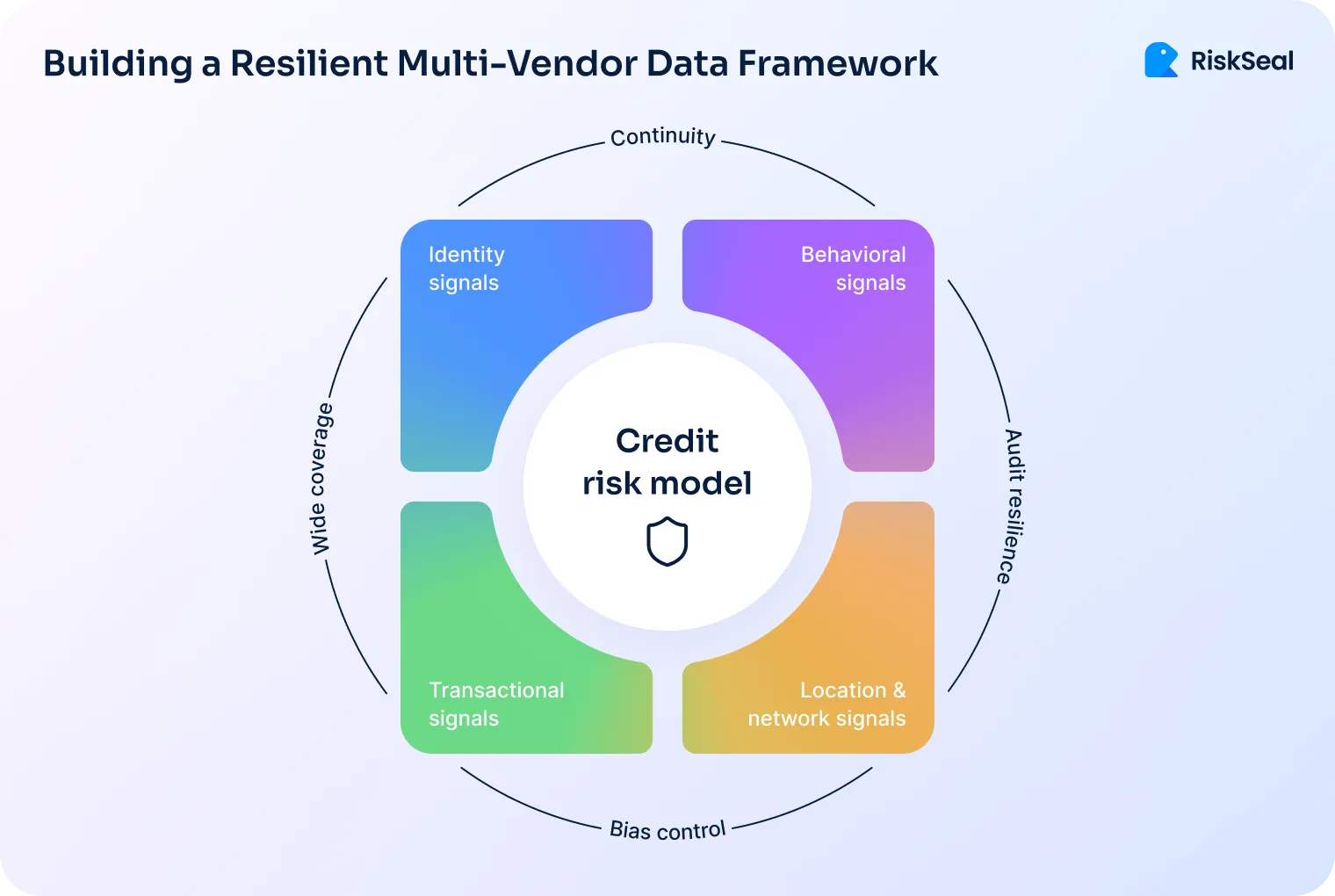
A robust credit model blends identity, behavioral, and transactional signals. Each layer offsets the weaknesses of the others:
- Technical layer. IP reputation, device fingerprint, email age, and phone risk score.
- Behavioral layer. Registration velocity, subscription churn, online purchasing rhythm.
- Transactional layer. Payment consistency, spending pattern variance.
Together, these form a multidimensional view of creditworthiness that isn’t dependent on any one category.
If one signal source degrades or becomes temporarily unavailable, the others maintain predictive stability.
Cross-validate signals to prevent over-weighting and bias
Strong models don’t just collect data; they balance it.
Cross-validation across diverse data types ensures that no single category overpowers the model’s decision weight.
For example, imagine an alternative credit model drawing 40% of its predictive power from phone intelligence, 30% from digital behavior, and 30% from subscription analysis.
If phone data suddenly becomes unavailable, performance drops. But not catastrophically.
In contrast, a model where 80% of predictive weight rests on one source could fail under the same scenario.
This approach not only enhances predictive accuracy but also builds tolerance against external shocks.
Engage parallel data vendors to improve continuity and coverage
Diversity isn’t only about signal types. It’s also about data provenance.
Each vendor collects and processes data differently. Coverage, quality, and refresh cycles vary widely.
By blending multiple providers for the same signal type, lenders achieve redundancy and mitigate bias.
This multi-vendor approach has three major advantages:
- Continuity. If one vendor goes offline, another continues feeding the model.
- Bias control. Different methodologies prevent systemic skew from a single dataset.
- Audit resilience. Regulatory reviews can trace results across distributed inputs.
This multi-vendor setup strengthens continuity and transparency, helping lenders catch vendor issues early.
How to audit and reduce vendor dependence before it’s too late
A practical audit framework helps lenders detect and mitigate vendor risk before it becomes systemic.
Step 1. Inventory model inputs
Map every data feed your scoring model consumes. Group features by vendor and quantify the proportion of model variance tied to each source.
This gives a clear picture of where concentration risk lives inside your real-time credit scoring pipeline.
Step 2. Simulate outages
Turn off one feed at a time and observe the performance impact.
If removing a single vendor causes a sharp accuracy drop or a workflow failure, you’ve identified a single point of failure that needs immediate attention.
Step 3. Build redundancy into your credit data supply chain
For every critical signal category – device, identity, and behavior – integrate at least one backup feed or proxy measure.
To make redundancy practical and sustainable:
- Use vendor-agnostic APIs or ingestion layers to standardize formats and simplify future integrations.
- Regularly benchmark multiple providers on the same use case to track performance and coverage over time.
- Employ modular model architectures that allow quick signal substitution without retraining the entire model.
Building this flexibility early makes future adaptation faster, cheaper, and far less disruptive.
Step 4. Run feature importance analysis
Identify “overweight” variables that dominate predictions.
Look for correlated features – multiple variables derived from the same vendor data often inflate influence and hide bias.
Step 5. Check explainability and fairness
Can you clearly articulate what each major feature represents and why it matters?
If not, you may face explainability gaps under regulatory review. Transparent feature mapping is critical for both compliance and internal trust.
Vendor-dependence checklist for quarterly model reviews
Quarterly reviews help lenders confirm that no single provider can disrupt scoring, onboarding, or fraud controls. The checklist below outlines the key items every team should verify.
- No single vendor provides more than 50 % of input features.
- At least one redundant data source exists per critical signal type.
- Explainability dashboards trace each vendor’s contribution.
- Validation reports simulate vendor-outage impacts annually.
- Procurement and compliance teams review vendor risk jointly.
This framework turns data diversity into a governance asset, not just a technical safeguard.
RiskSeal as an alternative credit data diversity enabler
At RiskSeal, we view data diversity as essential infrastructure for modern credit risk.
Our platform is designed not as a single-source vendor, but as a signal orchestrator. Our system harmonizes multiple categories of alternative data into one coherent framework.
We integrate and enrich signals across four primary layers:
- Digital footprint intelligence. Email, phone, and IP data to establish trust and identity consistency.
- Behavioral and engagement patterns. Signals of reliability drawn from online activity and subscription stability.
- Cross-lender intelligence. Detecting repeated identifiers and multi-account risk across institutions.
By combining these dimensions, RiskSeal avoids relying on any single data signal. We focus on stability and consistency across all data inputs.
Credit decisions are only as strong as the data behind them. That’s why we prioritize consistent, reliable data feeds. Lenders should never see unexplained approval changes or score drift.
RiskSeal delivers each signal through a transparent and explainable framework. That way, risk teams get clear visibility into how data behaves and how it affects outcomes.
If a data provider changes its policy or systems, our platform adapts quickly. We stabilize inputs, reduce disruptions, and keep model performance predictable.
We designed a system that keeps all data transparent, stable, and audit-ready. Our clients stay in full control of every source used in their models. This design prevents vendor lock-in.
This balanced, resilient design has secured RiskSeal a spot among top alternative data providers. It gives lenders clear visibility into data sources, ensuring auditability and compliance with fairness standards.
Final thoughts on building scoring systems that can survive shocks
The data powering your credit models is both your greatest asset and your greatest hidden risk.
A single-point dependency, no matter how sophisticated, can unravel performance, compliance, and continuity overnight.
Strong signals matter, but the model behind them must stay resilient. A stable system should withstand changes in a vendor or the temporary loss of an individual variable without breaking.
By diversifying signals, auditing dependencies, and building vendor-agnostic architectures, lenders can safeguard their models against the inevitable changes in the data landscape.
Credit risk is about seeing the unseen. That includes the risks hidden inside your own data supply chain.
See more

Alright, you've changed your scorecards by using alternative data. How can you check if they work well? What metrics you should measure? Check out the article.

.webp)
Explore key trends in alternative credit scoring that empower fintechs to assess unbanked populations.
Discover four practical ways to strengthen consumer credit risk in 2026 with real-time underwriting, alternative data, smarter collections, and compliance-ready AI.